UPDATE: Thanks to the keen eyed Dr. Zen, I would like to…
Crowdsourcing Hypotheses: The #SciFund Data Challenge!
Welcome back, all. It’s been a few months, and I hope everyone has been enjoying the great science updates from a variety of projects and is still basking in #SciFund’s warm glowing warming glow. We’re even starting to gear up for #SciFund 2, Electric Boogaloo, so keep your eyes peeled.
But before we jump into round 2, Jai and I wanted to know more about round 1. What made for a successful project? How does a crowdfunded proposal compare to a non-crowdfunded grant proposal? What do you need to do to make #SciFund work for you?
To get at these questions and more, we administered a survey to the participants of #SciFund, and we’re starting to analyze it. We have a lot of ideas about relationships and hypotheses to test, but, in the spirit of crowdsourcing, we wanted to crowdsource some of this part of the project to you – the hypothesis generation. I’d say we’d open up the data, but, sadly, cannot due to Human Subjects requirements (see end of this post for an explanation).
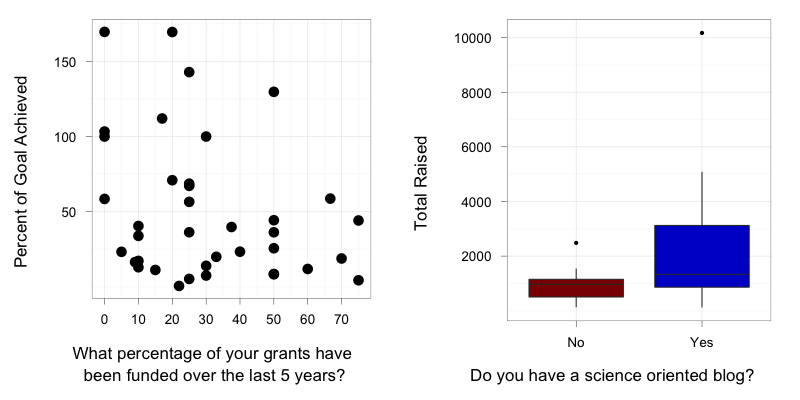
So, below the cut is the survey we administered as well as the data fields from Dr. Zen’s excellent efforts. Take a look at it, and post any hypotheses or analyses you want to see done! Feel free to get as fancy, detailed, or nutty as possible, bearing in mind that we have 48 data points, and some of the data are continuous and some categorical.